
Date:Apr 8, 2021
From DUT-RU International School of Information Science & Engineering
By Jing Jiayi, Wan Fang, Wang Zhihui, Jia Qi, Ye Xinchen
Recently, on the basis of intelligent visual perception, the Institute of Computer Geometry and Intelligent Media Learning (CGIML) of DUT-RU International School of Information Science & Engineering (ISE) made four high-quality scientific research achievements in the fields of low-light image enhancement, robust image stitching, depth map restoration, and 3D target detection, which have been accepted by 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), where acceptance rate is only 23.71 percent (1663/7015).
As an A-class conference on the CCF list, CVPR ranks first among all magazines and conferences in engineering and computer science according to Google Scholar Metrics 2020. At present, part of these achievements have been applied to unmanned stereo visual perception equipment and underwater robots for target grasping.
Highly efficient low-light image enhancement
Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement, co-authored by Liu Risheng, Ma Long, Zhang Jiaao, Fan Xin, and Luo Zhongxuan, suggested a new method to efficiently enhance low-light images, making it more adaptive to real application.
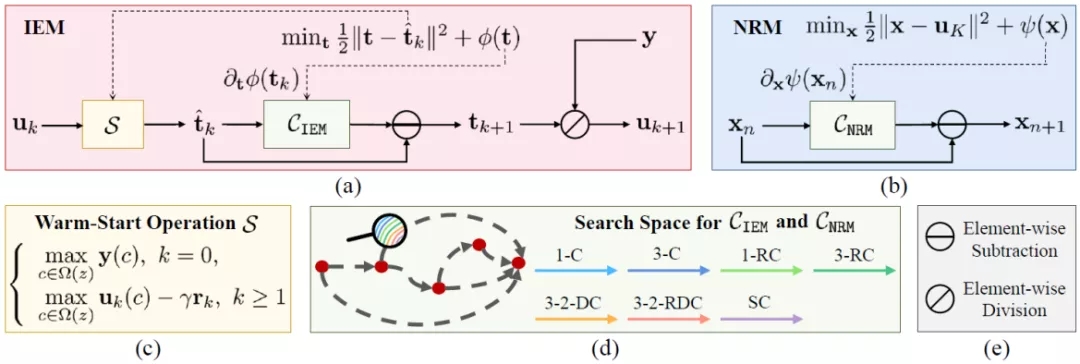
Low-light image enhancement plays very important roles in low-level vision areas. Recent works have built a great deal of deep learning models to address this task. However, these approaches mostly rely on significant architecture engineering and suffer from high computational burden. In this paper, they propose a new method, named Retinex-inspired Unrolling with Architecture Search (RUAS), to construct lightweight yet effective enhancement network for low-light images in real-world scenario. Specifically, building upon Retinex rule, RUAS first establishes models to characterize the intrinsic underexposed structure of low-light images and unroll their optimization processes to construct our holistic propagation structure. Then by designing a cooperative reference-free learning strategy to discover low-light prior architectures from a compact search space, RUAS is able to obtain a top-performing image enhancement network, which is with fast speed and requires few computational resources. Extensive experiments verify the superiority of our RUAS framework against recently proposed state-of-the-art methods. The project page is available at .
Highly robust image stitching
Leveraging Line-point Consistence to Preserve Structures for Wide Parallax Image Stitching, co-aothored by Jia Qi, Li Zhengjun, Fan Xin, Zhao Haotian, Teng Shiyu and Ye Xinchen, professors and students from DUT, and Longin Jan Latecki, a professor from Temple University, the United States. Generating high-quality stitched images with natural structures is a challenging task in computer vision.
In this paper, they succeed in preserving both local and global geometric structures for wide parallax images, while reducing artifacts and distortions. First of all, they match co-planar local sub-regions for input images. The homography between these well-matched sub-regions produces consistent line and point pairs, suppressing artifacts in overlapping areas. They explore and introduce global collinear structures into an objective function to specify and balance the desired characters for image warping, which can preserve both local and global structures while alleviating distortions. They also develop comprehensive measures for stitching quality to quantify the collinearity of points and the discrepancy of matched line pairs by considering the sensitivity to linear structures for human vision. Extensive experiments demonstrate the superior performance of the proposed method over the state-of-the-art methods by presenting sharp textures and preserving prominent natural structures in stitched images. Especially, their method not only exhibits lower errors but also the least divergence across all test images. Code is available at

High-quality depth map restoration
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution, co-authored by Sun Baoli, Ye Xinchen, Li Haojie, Wang Zhihui, and Xu Rui from DUT, and Baopu Li from Baidu Research, proposed depth map restoration method based on cross-task knowledge transfer, which overcame the limitations of existing color-guided method of scene depth restoration.
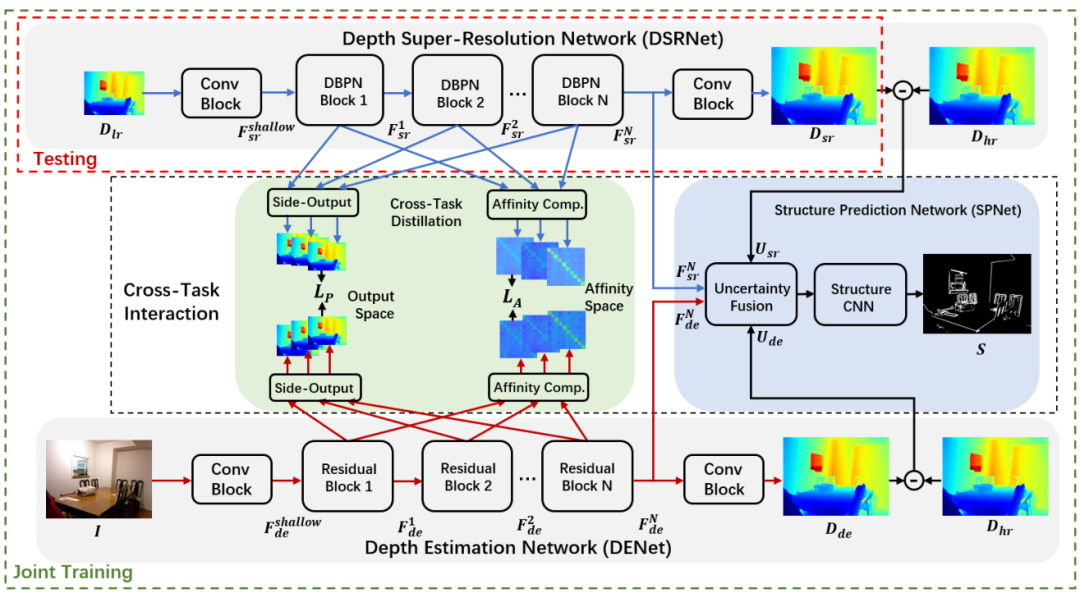
Existing color-guided depth super-resolution (DSR) approaches require paired RGBD data as training samples where the RGB image is used as structural guidance to recover the degraded depth map due to their geometrical similarity. However, the paired data may be limited or expensive to be collected in actual testing environment. Therefore, they explore for the first time to learn the cross-modality knowledge at training stage, where both RGB and depth modalities are available, but test on the target dataset, where only single depth modality exists. Their key idea is to distill the knowledge of scene structural guidance from RGB modality to the single DSR task without changing its network architecture. Specifically, they construct an auxiliary depth estimation (DE) task that takes an RGB image as input to estimate a depth map, and train both DSR task and DE task collaboratively to boost the performance of DSR. Upon this, a cross-task interaction module is proposed to realize bilateral cross-task knowledge transfer. First, they design a cross-task distillation scheme that encourages DSR and DE networks to learn from each other in a teacher-student role-exchanging fashion. Then, they advance a structure prediction (SP) task that provides extra structure regularization to help both DSR and DE networks learn more informative structure representations for depth recovery. Extensive experiments demonstrate that their scheme achieves superior performance in comparison with other DSR methods.A large number of experiments showed that the proposed algorithm had a lighter model, faster speed, and better performance without the assistance of high-resolution color information in practical deployment and testing.
High precision 3D target detection
Delving into Localization Errors for Monocular 3D Object Detection, co-authored by Li Haojie from DUT and Ma Xinzhu, Zhang Yinmin and Ouyang Wanli, DUT Alumni in Sidney University, Australia etc., analyzed the error sources of image-based 3D target detection by deconstructing the 3D target and gradually replacing the prediction elements, and solved key technical bottleneck of the accuracy and robustness of the existing 3D target detection algorithm by improving methods in sample labeling, loss function and sample weight. In this research, Estimating 3D bounding boxes from monocular images is an essential component in autonomous driving, while accurate 3D object detection from this kind of data is very challenging.
In this work, by intensive diagnosis experiments, they quantify the impact introduced by each sub-task and found the “localization error” is the vital factor in restricting monocular 3D detection. Besides, they also investigate the underlying reasons behind localization errors, analyze the issues they might bring, and propose three strategies. First, they revisit the misalignment between the center of the 2D bounding box and the projected center of the 3D object, which is a vital factor leading to low localization accuracy. Second, they observe that accurately localizing distant objects with existing technologies is almost impossible, while those samples will mislead the learned network. To this end, they propose to remove such samples from the training set for improving the overall performance of the detector. Lastly, they also propose a novel 3D IoU oriented loss for the size estimation of the object, which is not affected by ‘localization error’. They conduct extensive experiments on the KITTI dataset, where the proposed method achieves real-time detection and outperforms previous methods by a large margin.
In recent years, more than 100 papers in the fields of artificial intelligence and multimedia technology have been published in important journals and conferences such as IEEE TPAMI, TIP, TNNLS, TMM, NeurIPS, IJCAI, AAAI, CVPR, ECCV, ACM MM, etc.In the past year, more than 30 papers on theoretical and applied research of learnable optimization have been published in top conferences and journals (including NeurIPS, AAAI, IJCAI, ACM MM, TIP, TNNLS, etc.).On the basis of scientific research, the CGIML also tries to meet major national strategic needs. For example, the institute conducted research and development of 24-hour in-car 3D multiband visual perception units and underwater robots for target grasping, winning the first prize in major project physical bidding and making a breakthrough in underwater autonomous grasping.
Address: No.2 Linggong Road, Ganjingzi District, Dalian City,
Liaoning Province, P.R.C., 116024
Phone: +86-411-84706354 (Chinese/English)
Email: dutfao@dlut.edu.cn
Copyright 2010 dutdice.dlut.edu.cn. All Rights Reserved.




